Project Overview
Building an intelligent documentation search system requires combining web crawling, text processing, embedding generation, and sophisticated search capabilities. This blog explores a comprehensive implementation that crawls Supabase documentation, extracts and processes HTML content, generates local embeddings, and implements both semantic and hybrid search functionality with LLM evaluation capabilities.
Technical Architecture
Web Crawling Implementation
The foundation of this system starts with intelligent web crawling designed specifically for documentation sites. The crawler implementation uses a sophisticated approach to navigate and extract content from the Supabase documentation systematically.
const BASE = 'https://supabase.com';
const START_PAGES = [
`${BASE}/docs`,
`${BASE}/docs/guides/database/`,
`${BASE}/docs/guides/auth`,
`${BASE}/docs/guides/storage`,
`${BASE}/docs/guides/realtime`,
`${BASE}/docs/guides/functions`,
`${BASE}/docs/guides/ai`,
`${BASE}/docs/guides/cron`,
`${BASE}/docs/guides/queues`,
`${BASE}/docs/reference`
];
async function crawl(pageUrl: string): Promise<void> {
if (visited.has(pageUrl)) return;
visited.add(pageUrl);
try {
const { data: html } = await axios.get(pageUrl);
const $ = cheerio.load(html);
const relativePath = pageUrl
.replace(BASE, '')
.replace(/^\//, '')
.replace(/\/$/, '')
.replace(/\//g, '_') || 'docs_home';
const filename = path.join(OUTPUT_DIR, `${relativePath}.html`);
fs.mkdirSync(path.dirname(filename), { recursive: true });
fs.writeFileSync(filename, html, 'utf-8');
console.log(`Saved: ${filename}`);
// Find and crawl internal links
$('a[href]').each((_i, el) => {
const href = $(el).attr('href');
if (!href) return;
const absolute = url.resolve(pageUrl, href);
// Only follow internal docs pages
if (absolute.startsWith(`${BASE}/docs`) && !visited.has(absolute)) {
crawl(absolute); // No await = concurrent crawling
}
});
} catch (err: any) {
console.error(`Error crawling ${pageUrl}:`, err.message);
}
}
The crawling process prioritizes comprehensive coverage while maintaining efficiency, ensuring that all relevant documentation sections are captured for subsequent processing.
### HTML Text Extraction Pipeline
Raw HTML content requires careful processing to extract meaningful text while preserving document structure. The extraction pipeline implements multiple strategies to handle diverse HTML structures commonly found in documentation sites.
**Text Extraction Process:**
- **HTML Parsing**: Uses robust parsing libraries to handle malformed HTML gracefully
- **Content Filtering**: Removes navigation elements, advertisements, and non-content sections
- **Structure Preservation**: Maintains heading hierarchy and paragraph relationships
- **Text Cleaning**: Normalizes whitespace, removes formatting artifacts, and handles special characters
```javascript
function extractTextFromHTML(html: string, fileName: string) {
try {
const $ = cheerio.load(html);
$('script, style, nav, footer, header, aside, .navigation, .menu, .sidebar').remove();
let title = $('title').text().trim();
if (!title) {
title = $('h1').first().text().trim();
}
if (!title) {
title = fileName.replace(/\.html$/, '').replace(/_/g, ' ').replace(/#/g, ' - ');
}
let content = '';
const contentSelectors = [
'main',
'article',
'.content',
'.main-content',
'.prose',
'.document-content',
'[role="main"]',
'section',
'.container'
];
for (const selector of contentSelectors) {
const element = $(selector).first();
if (element.length && element.text().trim().length > 100) {
content = element.text();
break;
}
}
if (!content || content.length < 100) {
content = $('body').text();
}
const cleanText = content
.replace(/\s+/g, ' ')
.replace(/\n\s*\n/g, '\n')
.replace(/[^\w\s\.\,\!\?\;\:\-\(\)]/g, ' ')
.trim();
const wordCount = cleanText.split(/\s+/).filter(word => word.length > 0).length;
return {
title: title || 'Untitled',
content: cleanText,
wordCount,
charCount: cleanText.length,
originalLength: html.length
};
} catch (error) {
console.error(`Error parsing HTML for ${fileName}:`, error);
return {
title: fileName,
content: '',
wordCount: 0,
charCount: 0,
originalLength: html.length
};
}
}The extraction process converts complex HTML documents into clean, structured text suitable for embedding generation while preserving the logical organization of the documentation.
Local Embedding Generation
Local embedding generation provides several significant advantages over cloud-based solutions. The implementation utilizes open-source embedding models to process the extracted documentation text.
Benefits of Local Embeddings:
- Complete Control: Full customization of the embedding process to match specific documentation characteristics
- Cost Efficiency: No per-token charges or API limitations
- Privacy: Sensitive documentation content remains on local infrastructure
- Performance: Reduced latency and dependency on external services
- Domain Adaptation: Ability to fine-tune models for technical documentation terminology
The local embedding pipeline processes text chunks through optimized batch operations, generating high-quality vector representations that capture the semantic meaning of the documentation content.
Database Schema and Storage
The system employs a sophisticated database schema designed to support both storage and retrieval operations efficiently:
Documents Table (documents_text):
- Stores original HTML content, extracted text, and metadata
- Includes word count and character count for analytics
- Maintains file paths for content traceability
- Contains embedding vectors for semantic search
Evaluation Tables:
- llm_evaluations: Tracks model performance across different queries
- benchmark_sessions: Manages evaluation campaigns and testing scenarios
- chat_logs: Records user interactions and system responses
This schema design supports both operational search functionality and comprehensive evaluation capabilities.
Search Implementation
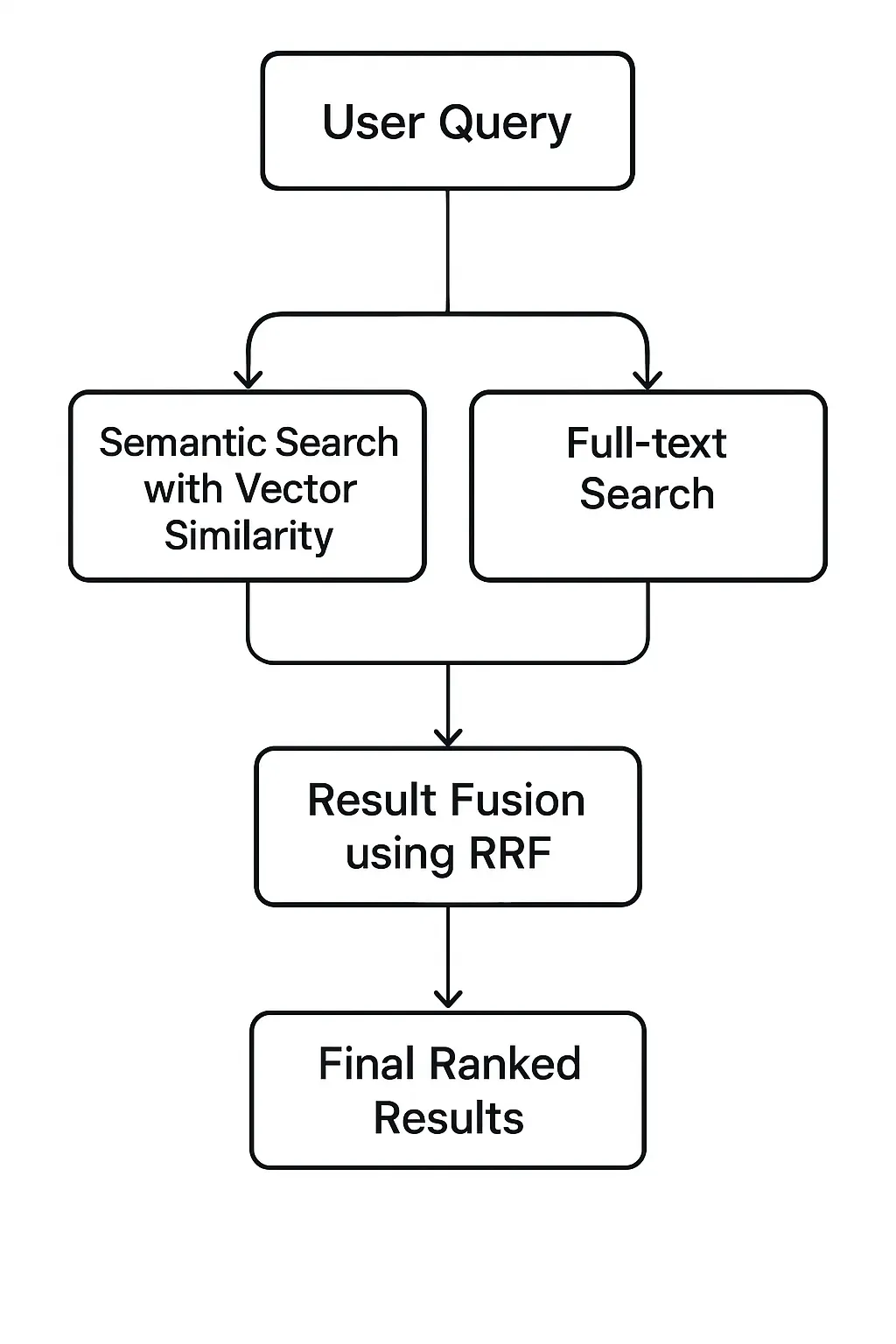
Semantic Search Capabilities
Semantic search leverages dense vector embeddings to understand query meaning rather than relying solely on keyword matching. The implementation uses cosine similarity to find documents that are conceptually related to user queries, even when exact keywords don’t match.
Semantic Search Advantages:
- Context Understanding: Captures conceptual relationships between queries and documentation
- Synonym Handling: Finds relevant content regardless of specific terminology used
- Multi-concept Queries: Effectively processes complex questions spanning multiple topics
Traditional Keyword Search
The system maintains traditional keyword search capabilities using sparse vector methodologies. This approach excels at finding exact matches and handles specific technical terms, error messages, and code references that users frequently search for in documentation.
Keyword Search Strengths:
- Exact Matching: Precise results for specific terms, function names, or error codes
- Technical Terminology: Effective handling of domain-specific language
- User Expectations: Many users expect exact keyword matches for certain query types
Hybrid Search Fusion
The hybrid approach combines semantic and keyword search results through sophisticated fusion techniques. The system uses reciprocal rank fusion (RRF) to merge results from both search methods, creating a unified ranking that leverages the strengths of each approach.
Fusion Benefits:
- Comprehensive Coverage: Captures both exact matches and conceptually related content
- Balanced Results: Prevents either approach from dominating inappropriately
- User Satisfaction: Meets diverse user expectations and search patterns
- Query Adaptability: Automatically adjusts to different query types and intentions
For Reference: https://github.com/krishvsoni/embedding-local/blob/master/src/db/generate-embeddings-local.ts
LLM Evaluation Framework
Performance Metrics
The evaluation system implements comprehensive metrics to assess LLM performance across multiple dimensions:
Response Quality Metrics:
- BLEU Score: Measures translation quality and text similarity
- ROUGE Score: Evaluates summarization and content overlap
- Semantic Similarity: Assesses meaning preservation across responses
- Coherence Score: Measures logical consistency and flow
System Performance Metrics:
- Response Time: Tracks query processing latency
- Token Count: Monitors computational efficiency
- Cost Estimates: Evaluates resource utilization
Reference Code: https://github.com/krishvsoni/Supabot/blob/master/lib/llm-evaluation-enhanced.ts
Future MCP Server Architecture
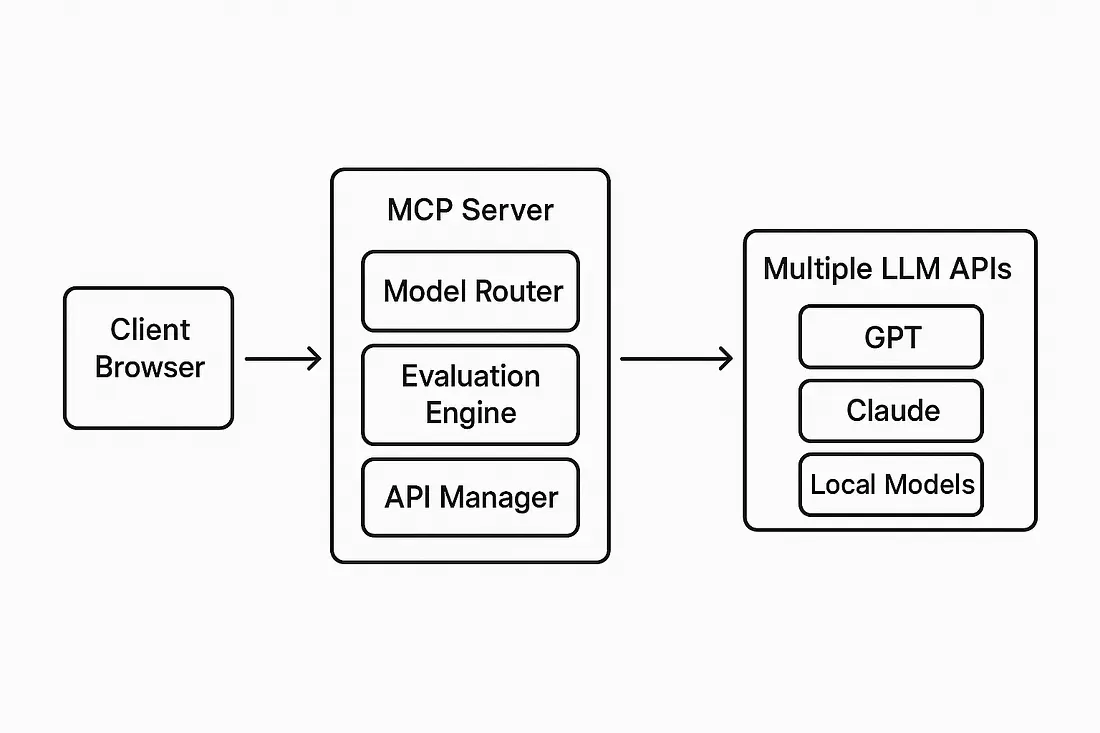
The planned MCP server integration architecture demonstrates how the system will evolve to support multiple LLM providers, centralized evaluation, and enhanced client-server communication while maintaining the core local processing benefits.
Key Implementation Highlights
The architecture showcases several important aspects of this implementation:
- Modular Design: Each component operates independently, allowing for easier maintenance and scaling
- Local Processing: The emphasis on local embedding generation reduces dependencies and costs while maintaining privacy
- Hybrid Approach: The combination of semantic and lexical search provides comprehensive retrieval capabilities
- Scalable Storage: PostgreSQL with pgvector offers both relational and vector database capabilities in a single system
- Future-Ready: The MCP server integration path shows how the architecture can evolve to support more advanced AI workflows
These architectural decisions make it easier to understand the technical concepts and data flow in the semantic search system, perfect for documentation, presentations, or explaining the architecture to stakeholders.
Conclusion
This comprehensive documentation search system demonstrates the power of combining modern web crawling techniques with local embedding generation and hybrid search capabilities. The architecture provides a solid foundation for building intelligent documentation assistants while maintaining control over data privacy and processing costs.